最近在做一个用Spark洗数据的工作,其中的一个步骤需要将宽数据转换为长数据,发现Spark里面并没有原生的方法实现这样的效果,后面发现可以利用explode方法,间接实现这样数据的转换,本文介绍整个思路。
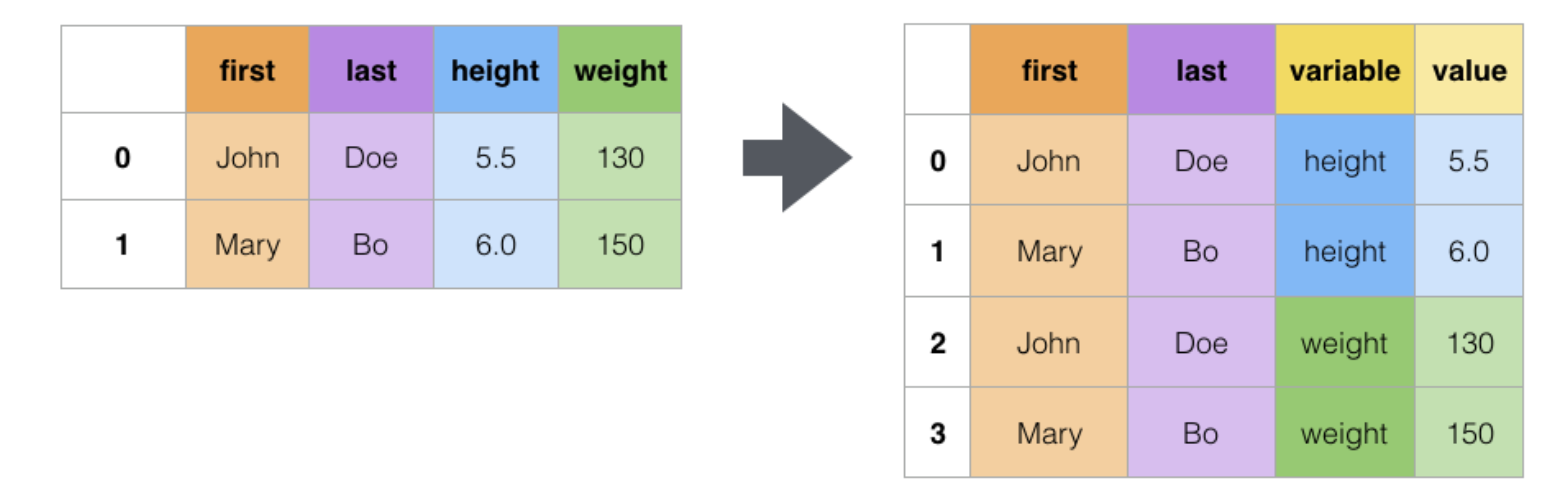
![Melt函数实现的效果(图引用自https://pandas.pydata.org/docs/user_guide/reshaping.html]() Melt函数实现的效果(图引用自https://pandas.pydata.org/docs/user_guide/reshaping.html
Melt函数实现的效果(图引用自https://pandas.pydata.org/docs/user_guide/reshaping.html
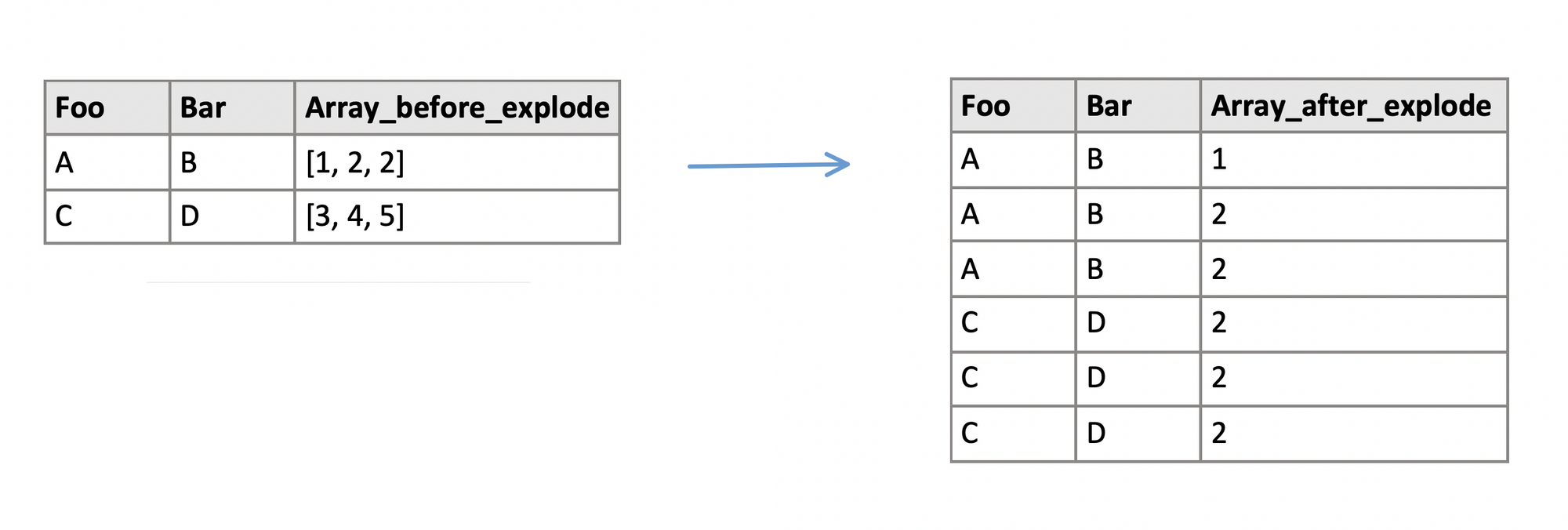
explode 方法可以将DataFrame一行中ArrayType或者StructType的集合数据下每一项,提取出来单独作为新DataFrame的一行中的一项,实现从一个集合到多个个体的转换,一行到多行的转换。具体实现效果如下:
![explode方法实现效果]() explode方法实现效果
explode方法实现效果
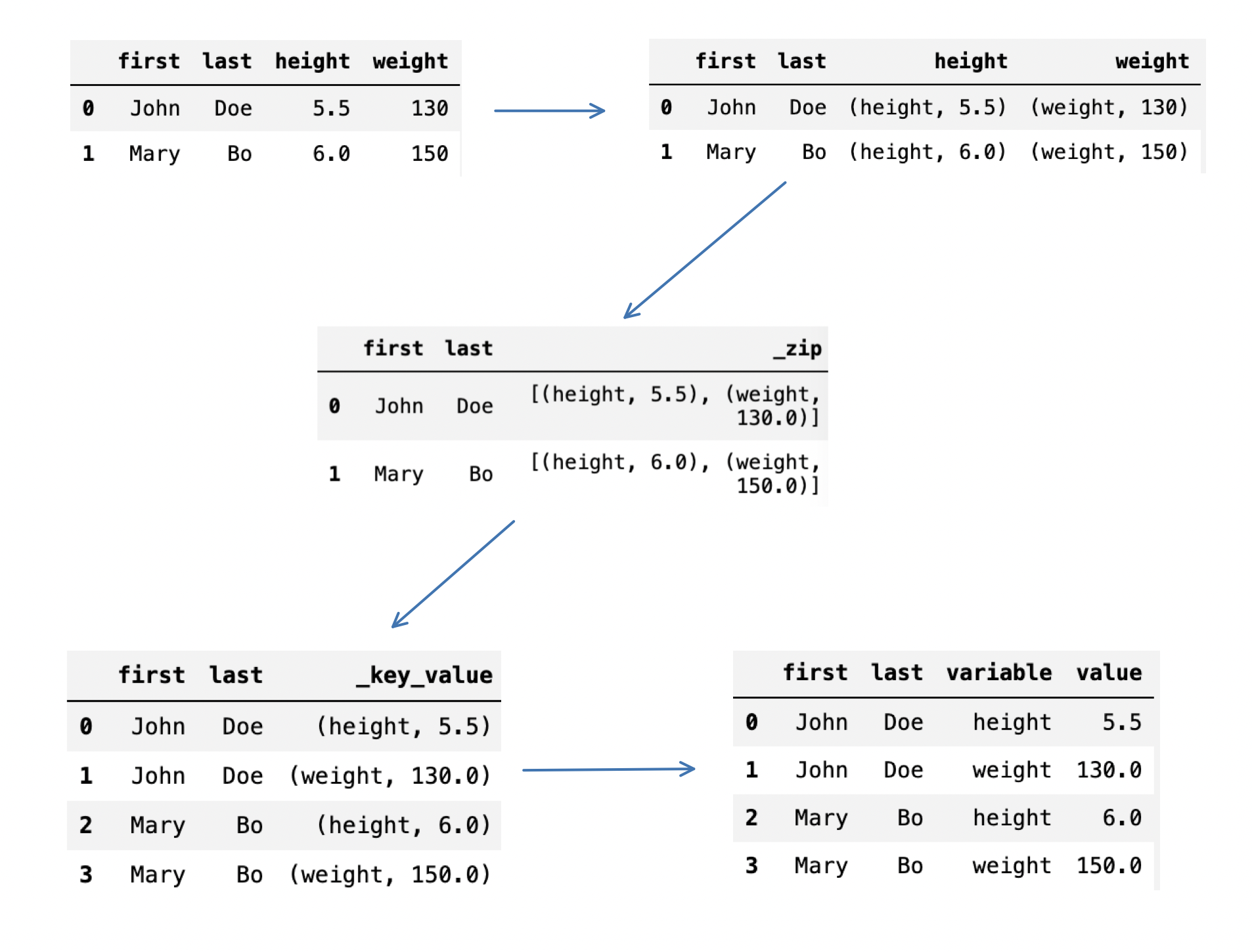
回到在Spark中实现melt方法,我们可以首先将需要melt的列合并ArrayType的集合,集合中的每个元素以(variable_name, variable_value)的StructType呈现,再利用explode 方法进行一到多的拓展,最后再将(variable_name, variable_value)分成两列即可,示意图如下:
![Spark中melt方法实现的流程]() Spark中melt方法实现的流程
Spark中melt方法实现的流程
我将最后代码整理如下,函数采用了和Pandas中类似的参数命名方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
def sparkMelt(frame, id_vars=None, value_vars=None, var_name=None, value_name=None):
"""
Pandas melting functions implemented in Spark
Args:
frame (Spark DataFrame): Spark dataframe to work on.
id_vars (list, optional): Column(s) to use as identifier variables. Defaults to None.
value_vars (list, optional): Column(s) to unpivot. If not specified, uses all columns that are not set as id_vars. Defaults to None.
var_name (list, optional): Name to use for the ‘variable’ column. Defaults to None. If None, use 'variable'.
value_name (list, optional): Name to use for the ‘value’ column. Defaults to None. If None, use 'value'.
Returns:
[Spark DataFrame]: Unpivoted Spark DataFrame.
"""
id_vars = id_vars if not id_vars else frame.columns
value_vars = [col_name for col_name in frame.columns if col_name not in id_vars] \
if not value_vars else value_vars
# if value_vars is None, no columns need to be melted
if not value_vars:
return frame
var_name = 'variable' if not var_name else var_name
value_name = 'value' if not value_name else value_name
col_lst = ['height', 'weight']
for col_name in col_lst:
frame = frame.withColumn(col_name,
F.struct(F.lit(col_name).alias('var_name'), F.col(col_name).alias('var_value')))
frame = frame.withColumn('_zip', F.array(*col_lst)) \
.withColumn('_key_value', F.explode('_zip')) \
.withColumn(var_name, F.col('_key_value')['var_name']) \
.withColumn(value_name, F.col('_key_value')['var_value'])
df_col = [col_name for col_name in frame.columns if col_name not in (
*col_lst, '_zip', '_key_value')]
frame = frame.select(*df_col)
return frame
|